

Softeq helped a major US telecom company create a custom media streaming solution for digital signage. The solution allows retailers and advertising agencies to broadcast promotional content on digital displays installed in public places.
Table of Contents
The System’s Functional Components Overview
Here's the system's functional components rundown. It includes:
- USB flash-like devices running on customized Android firmware
- A web-based admin portal, which enables advertisers to upload media content, set up the devices, manage marketing campaigns, and generate reports
- Mobile applications, which partially mirror the functionality of the admin portal and help users control media content output
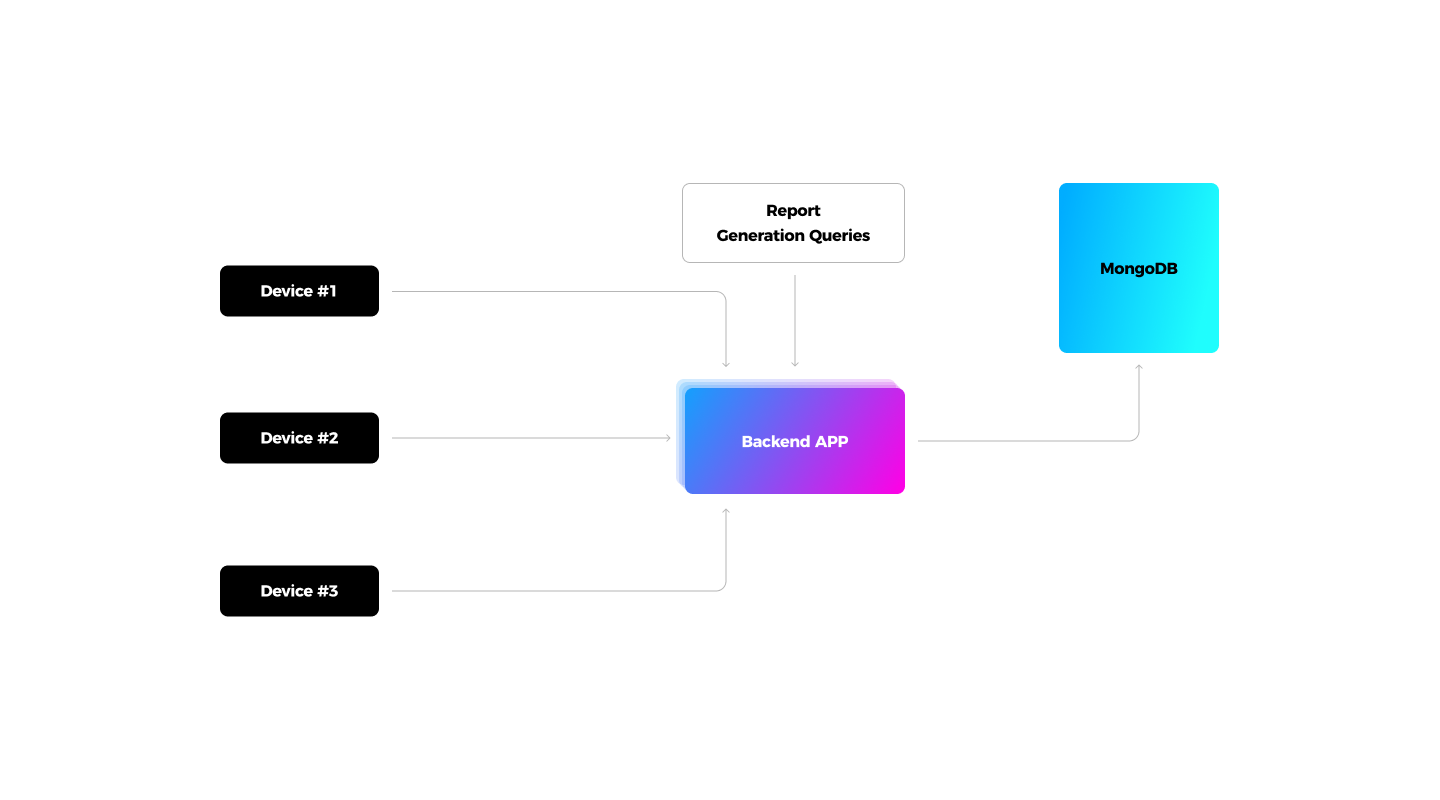
- A secure back end underpinning the system’s business logic: data storage, device location tracking (GPS), user role management, remote support, etc.
Besides digital content distribution, the system helps evaluate campaign performance. For this, the gadgets collect ad impression data for particular campaigns and content types and send the metrics to the back end on an hourly basis. An advertiser can request campaign performance data over a given period and view the metrics via the admin portal.
Technical Challenge
To store the data, we initially chose MongoDB, which creates a unique ID for every file and arranges the documents in a table, and implemented the reporting functionality using the MongoDB Aggregation Pipeline. The solution worked well until the database grew to 20 million records.
After that, the following issues emerged:
- The metrics collection slowed down considerably
- The system no longer distributed user requests across multiple servers, which increased the server response time
- Following a user’s request, the system had to load all existing data instead of fetching the data for specific columns
- The MongoDB replicas ran out of memory during long aggregation sessions
To solve the issues affecting the system’s performance, our team tried:
- Pre-aggregating ad performance data on a daily basis. The approach allowed us to reduce data volumes by up to 800% and significantly reduce the report generation time
- Implementing covering indexes. A covering index contains all of the data mentioned in a query, so the server doesn’t have to retrieve the data from the main table to generate ad performance reports
With those improvements, we managed to stabilize the system’s performance until it became necessary to scale the back end capacity to support the growing number of devices. To optimize the query speed, we needed a more scalable back-end solution.
Choosing an Alternative Tech Stack to Speed up IoT Analytics
Due to several technical limitations, MongoDB cannot efficiently process aggregation queries:
- No clustered index. MongoDB uses a B-tree index. It is not selective, so the database must read all the documents stored in it to find the information users need
- Data storage by rows. To generate an ad performance report, the back end needs to load the data from all the columns that comprise the database table
- MongoDB does not support data compression. Data compression helps reduce the size of a database and improve I/O-intensive workloads (because the data is stored in fewer pages and queries need to read fewer pages from the disk)
When considering an alternative to MongoDB, we were looking for a back-end solution that would help the team override these limitations.

Eventually, we chose AWS Redshift — a fully managed petabyte-scale data warehouse service in the cloud, which is cost-efficient, ensures stable performance, and is DevOps-friendly.
Major advantages include:
- AWS Redshift allows developers to add more computing nodes to the database in mere hours
- As a columnar database, AWS Redshift can process queries and perform analysis faster than row-based databases
- It is based on pgSQL, therefore our customer’s IT department wouldn’t have to learn a new programming language
- AWS Redshift uses clustered indexes instead of a B-tree and can filter millions of table rows without additional data structure
- AWS automates cluster operations, which saves on configuration and deployment efforts
- Data warehouse for the whole system
- Service level agreement (SLA) — 99,9%

AWS Redshift Overview
An AWS Redshift cluster contains a single leader node, which processes queries and distributes tasks across compute nodes. After the compute nodes complete their tasks, the leader node merges the results and sends the data to the client. Redshift provides sort keys instead of a B-Tree, which helps narrow down search criteria, compress data to optimize storage space, and store information in columns instead of rows.
AWS Redshift is also integrated with the AWS S3 data storage solution. Thus, we can simply dump JSON data from MongoDB to JSON files, upload them to S3, and import the information from S3 to AWS Redshift. In the same way, we can upload retired data to S3 after a specified period of time.
Results
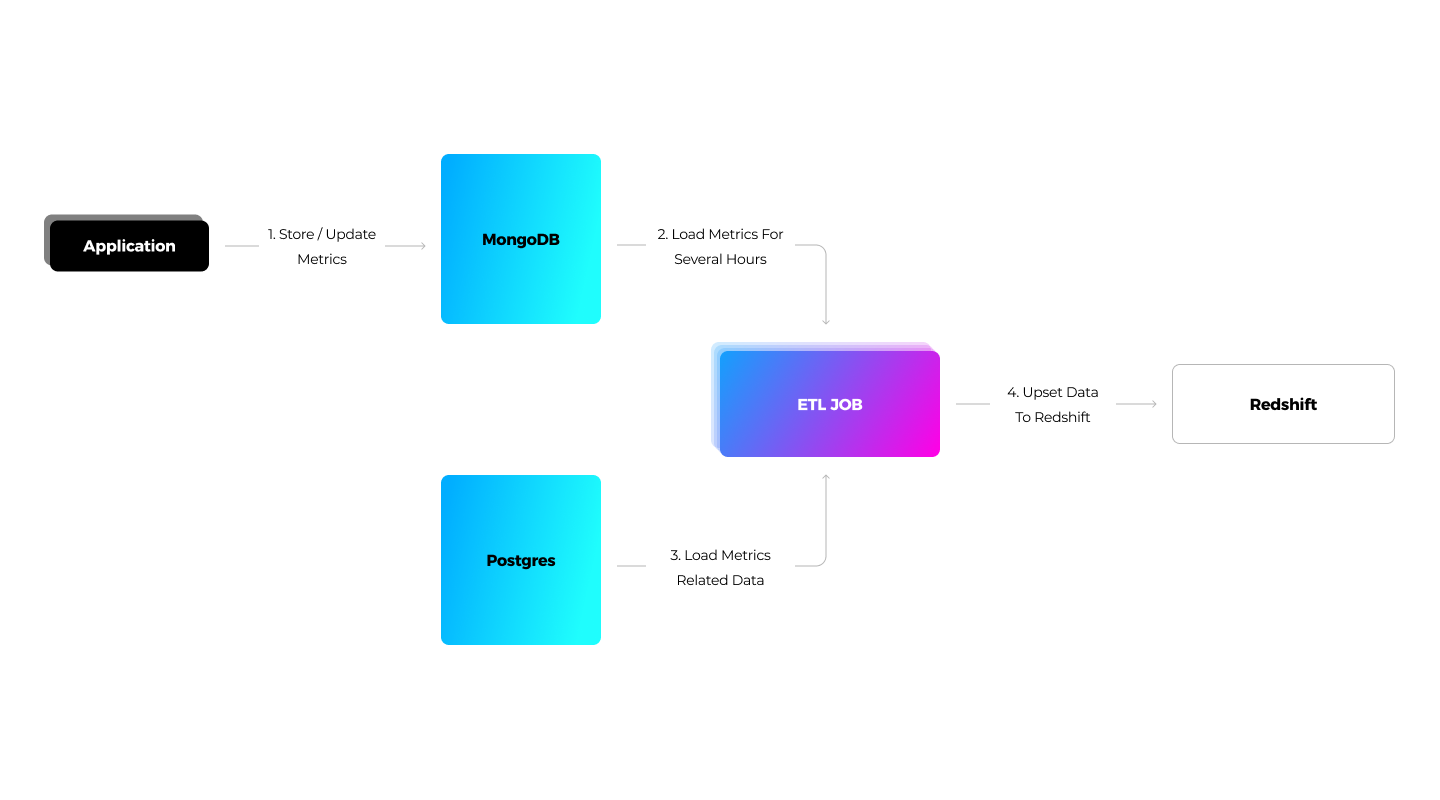
The media streaming solution uses MongoDB to process ad performance metrics. ETL jobs are responsible for the batch loading of the metrics from MongoDB/Postgres to Redshift. Thanks to the modified_date_time column, we know when the data has been modified. To implement the ETL jobs, we used Spring Boot with the Redshift JDBC Driver. For report generation, the application constructs and directly sends queries to Redshift with the Redshift JDBC driver.
 Also, we benchmarked our solution and found that the maximum possible count of stored data for a two-node cluster is 2 billion records (for our use case). In this case, it would take the system approximately five minutes to produce a report.
Also, we benchmarked our solution and found that the maximum possible count of stored data for a two-node cluster is 2 billion records (for our use case). In this case, it would take the system approximately five minutes to produce a report.
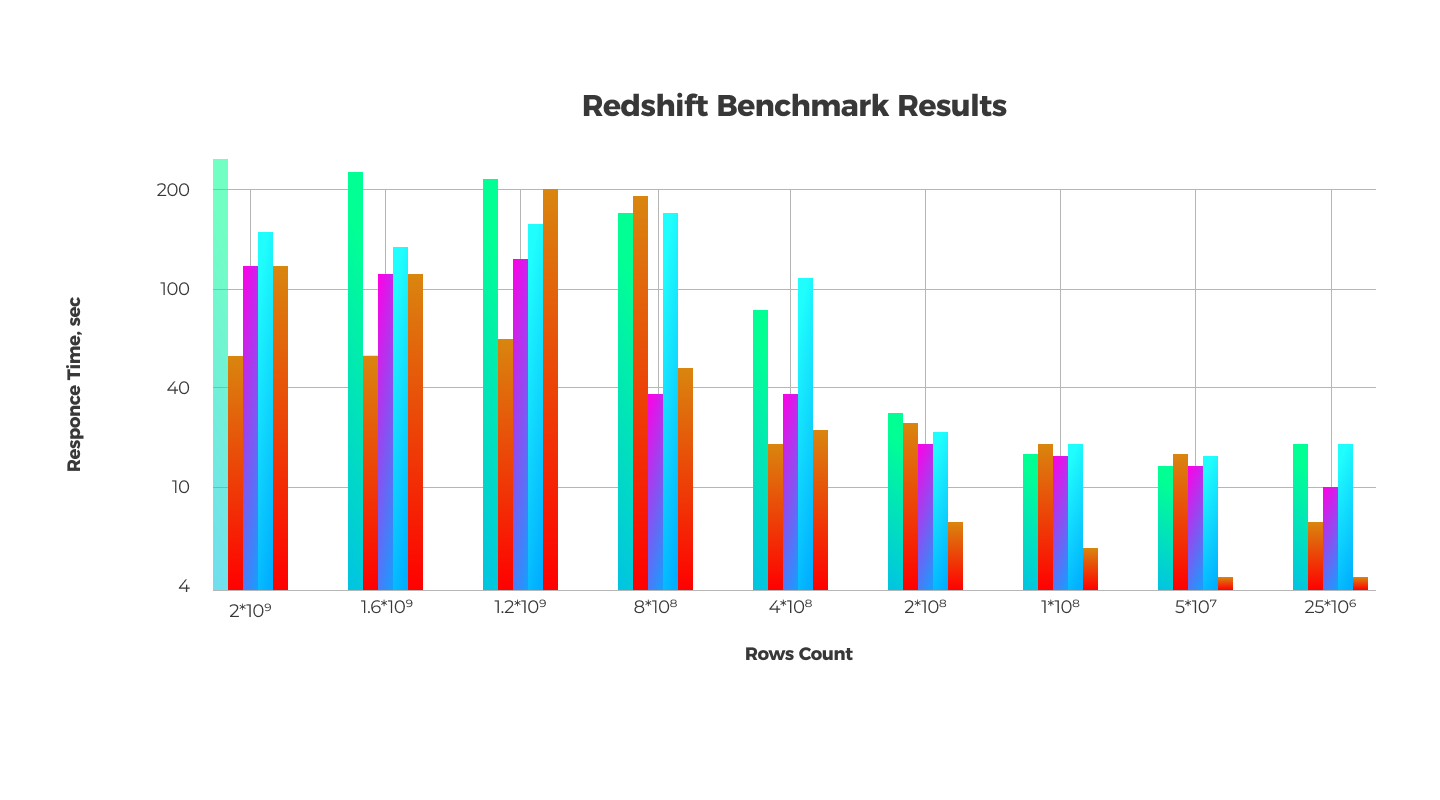 To compare the performance of MongoDB and Redshift, we can select cases when the database would contain 25 million records. It would take MongoDB 12 minutes to generate a report following a user’s query; AWS Redshift can do the job in approximately 20 seconds. Thus, we managed to do the same amount of data processing and analytics 36 times faster.
To compare the performance of MongoDB and Redshift, we can select cases when the database would contain 25 million records. It would take MongoDB 12 minutes to generate a report following a user’s query; AWS Redshift can do the job in approximately 20 seconds. Thus, we managed to do the same amount of data processing and analytics 36 times faster.






